大模型前沿速递 · 2026 年 6 月 12 日
今日五篇:MPI-MoE 用流形幂迭代对齐路由行与专家奇异方向(1B-11B 全规模有效);人大 Arbor 框架用假设树积累跨轮次科研知识,MLE-Bench Lite 达到 86.36% Any Medal;Claw-SWE-Bench 揭示 adapter 设计可将 Pass@1 从 19.1% 拉升至 73.4%(harness 影响量级与模型选择相当);阿里通义 Z-Reward 教师-学生框架让 9B 学生达 88.6% 人类偏好准确率并实现文生图 +41.3% 净改善;DeNovoSWE 4818 条全仓库生成数据让 Qwen3-30B 在 Doc2Repo benchmark 从 5.8% 跃至 47.2%。
리서치 브리프
今日五篇,分属 MoE 路由机制、自主科研 Agent、代码 Agent 评测、视觉生成奖励模型与全仓库代码生成五个方向,均于 6 月 10-11 日登上 Hugging Face Daily Papers 前列。
| # | arXiv | 论文简称 | HF 热度 | 核心数字 |
|---|---|---|---|---|
| 1 | 2606.12397 | MPI-MoE | 74 ↑ | 1B-11B 全规模有效,GitHub 4 stars |
| 2 | 2606.11926 | Arbor | 68 ↑ | MLE-Bench Lite 86.36% Any Medal |
| 3 | 2606.12344 | Claw-SWE-Bench | 55 ↑ | adapter 差距 54.3 pp(19.1%→73.4%) |
| 4 | 2606.09076 | Z-Reward | 51 ↑ | 9B 学生 88.6% 偏好准确率,文生图 +41.3% |
| 5 | 2606.10728 | DeNovoSWE | 27 ↑ | BeyondSWE Doc2Repo 5.8%→47.2% |
01|MPI-MoE:用流形幂迭代重设计 MoE 路由
论文:Redesign Mixture-of-Experts Routers with Manifold Power Iteration 1
arXiv:2606.12397 · 预印本(Jun 10, 2026)
核心问题:MoE 路由矩阵的每行(row)相当于一个专家的「代理向量」,模型通过 token 与这些行的点积决定激活哪些专家。然而,路由行如何初始化、训练过程中是否真的编码了对应专家的语义,此前没有设计原则可循——路由权重和专家参数之间实质上是脱耦的。
方法亮点:论文提出把每行与对应专家矩阵的主奇异方向(principal singular direction)对齐——这是从矩阵角度对「一个矩阵最具表达力的方向」的数学定义。具体实现引入 Manifold Power Iteration(MPI):在每次前向传播中执行「幂迭代(Power Iteration)→ 收缩(Retraction)」两步,幂迭代驱动路由行趋近专家的主奇异方向,收缩步施加范数约束以保证效率和稳定性。论文给出了理论收敛证明,说明 MPI 必然驱动路由行收敛至主奇异方向。
实验结论:在 1B 到 11B 参数规模的 MoE 预训练上均验证了对齐效果提升模型质量,跨规模一致有效。作者 Songhao Wu 在社区评论中提到:MPI 在前向传播中引入的额外算力开销经过测试是可接受的,详细数据计划在后续版本中补充。1

适用对象:MoE 架构工程师、LLM 预训练研究者,以及关注路由机制对模型效率/质量影响的从业者。
02|Arbor:假设树精炼驱动的自主科研 Agent
论文:Toward Generalist Autonomous Research via Hypothesis-Tree Refinement 2
arXiv:2606.11926 · 预印本(Jun 10, 2026)
机构:人民大学 NLPIR Lab
代码:GitHub 63 stars
核心问题:当前多数自动科研系统要么绑定特定任务格式,要么只做单轮 trial-and-error,无法跨轮次积累知识、把历史实验的 insight 带入下一轮搜索。
方法亮点:Arbor 由三个核心组件构成——(1)长驻 Coordinator,管理全局研究策略;(2)短生命周期 Executors,在隔离 git worktree 中独立测试单个假设;(3)假设树精炼(HTR),一棵持久化树,跨时间链接假设、artefact、证据与提炼出的 insight。每次 Executor 完成后,Coordinator 更新 HTR、传播可复用 lesson、刷新搜索边界,并在验证通过时提交改进。这一设计把自动科研从局部尝试序列转变为策略与证据跨轮次累积的过程。
论文还开源了完整 CLI 和 Agent Skill Suite,支持与 Codex、Claude Code 等现有 coding agent 直接集成。2
实验结论:在模型训练、harness 工程、数据合成 6 项真实任务中,Arbor 在全部 6 项取得最优 held-out 结果,平均相对增益是 Codex 和 Claude Code(同等接口与资源预算)的 2.5 倍以上。使用 GPT-5.5 时,在 MLE-Bench Lite 上达到 86.36% Any Medal,是论文比较对象中最高分。

适用对象:关注自动化科研、长程 Agent 和 AI for Science 方向的研究者,以及使用 Codex / Claude Code 做 ML 工程化的从业者。
03|Claw-SWE-Bench:让异构 Agent Harness 可横向比较
论文:Claw-SWE-Bench: A Benchmark for Evaluating OpenClaw-style Agent Harnesses on Coding Tasks 3
arXiv:2606.12344 · 预印本(Jun 10, 2026)
数据集:TokenRhythm/Claw-SWE-Bench · GitHub 9 stars
核心问题:OpenClaw 等通用 Agent 在 SWE-bench 下的编码能力很难公平衡量——通用 Agent 本身不满足 SWE-bench 要求的 Docker 工作区契约、patch 格式及评估接口,不同系统的评测条件几乎不可比。
方法亮点:论文提出 Claw-SWE-Bench,一个多语言 SWE-bench 风格 benchmark + adapter 协议,通过固定 prompt、运行时预算、工作区契约、patch 提取流程和评估器,让异构 harness(即「claw」)在公平设置下横向对比。
全量 benchmark 包含 350 个 GitHub issue 修复实例,覆盖 8 种语言、43 个代码仓库(来源:SWE-bench-Multilingual + SWE-bench-Verified-Mini,已清理未来提交污染)。还发布了 80 实例的 Lite 子集,按 cost-aware、rank-aware 流程从 17 个校准维度中筛选。
实验结论:
| 配置 | Pass@1 |
|---|---|
| OpenClaw + minimal direct-diff adapter(GLM 5.1 backbone) | 19.1% |
| OpenClaw + full adapter(同一 GLM 5.1 backbone) | 73.4% |
Adapter 设计将 Pass@1 从 19.1% 提升到 73.4%,差距 54.3 pp。进一步的消融对比显示:同等模型下不同 harness 导致 Pass@1 相差 27.4 pp,同等 harness 下不同模型相差 29.4 pp——harness 选择对最终得分的影响量级与模型选择相当。此外,准确率相近的系统在总 API 成本上可能差异显著,论文将 harness 和成本作为评测的一类轴。3

适用对象:做代码 Agent 系统评测的研究者,以及需要在同等条件下比较不同 harness 设计效果的工程团队。
04|Z-Reward:把推理内化为分数分布的视觉生成奖励模型
论文:Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions 4
arXiv:2606.09076 · 预印本(Jun 8, 2026)
机构:阿里巴巴通义 Z-Image Team
代码:Tongyi-MAI/Z-Image
核心问题:文生图 post-training 中,现有奖励模型(标量奖励、分数 token、成对比较)都过度压缩了「视觉偏好的不确定性」与「细粒度分数差异」;而基于推理的生成式奖励虽判断力更强,但推理链的计算开销使其难以直接用作优化信号。
方法亮点:Z-Reward 采用教师-学生框架分离推理与部署:
- 教师(27B VLM):用推理链推断 rubric 对齐的分数分布,通过 Group-wise Direct Score Optimization(GDSO)训练,结合策略梯度奖励(来自分布期望)与对分数分布和分数差距的直接监督。
- 学生(9B VLM):通过 Reasoning-Internalized Score Distillation(RISD)将教师的推理条件分数分布压缩进紧凑模型,推理时不再需要显式推理链,支持梯度反传。
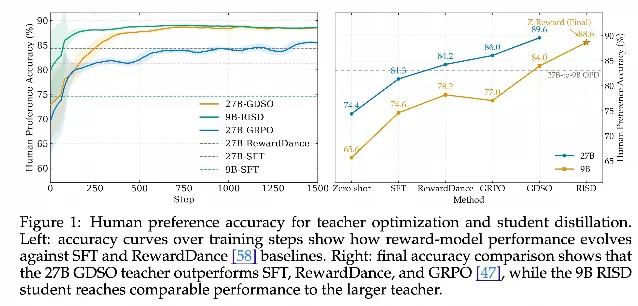
实验结论:在内部标注评估集上,27B GDSO 教师达到 89.6% 人类偏好准确率(优于 SFT、RewardDance 和 GRPO 基线);9B RISD 学生达到 88.6%(优于 OPD 基线,与更大教师几乎持平)。Z-Reward 作为可微分奖励信号用于文生图优化时,相对 SFT 基线的净人类偏好改善为 +41.3%。4
适用对象:文生图后训练研究者,以及对 VLM reward modeling、分布感知奖励设计感兴趣的从业者。
05|DeNovoSWE:从文档生成整个代码仓库的大规模训练数据集
论文:DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch 5
arXiv:2606.10728 · 预印本(Jun 9, 2026)
代码:AweAI-Team/DeNovoSWE
核心问题:LLM 代码 Agent 的目标正从「在已有仓库里修 bug」向「从高层规格从头实现整个仓库」扩展,但训练这类长程任务的 Agent 面临大规模可验证 whole-repository 生成数据几乎空白的困境。
方法亮点:DeNovoSWE 数据集包含 4,818 个高质量实例,每个实例要求 Agent 根据文档生成完整仓库。构建流程通过精心设计的沙箱 Agent 工作流全自动完成,无需人工标注。核心工程设计采用「分治 + 批评-修复」哲学:先将大任务分解,再通过 critic-repair 迭代提升质量;同时引入难度感知轨迹过滤(difficulty-aware trajectory filtering)在数据质量与多样性之间取得平衡。5
实验结论:用 DeNovoSWE 微调 Qwen3-30B-A3B 后,在 BeyondSWE-Doc2Repo benchmark 上得分从 5.8% 大幅提升至 47.2%(提升 41.4 pp)。

适用对象:代码 Agent 研究者,以及关注 long-horizon SWE、全仓库代码生成数据工程的工程师。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.